Rabbitmq详解及集群搭建
关于MQ
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求
特点
MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取或者订阅队列中的消息。MQ和JMS类似,但不同的是JMS是SUN JAVA消息中间件服务的一个标准和API定义,而MQ则是遵循了AMQP协议的具体实现和产品。
使用场景
在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量
关于RabbitMQ
RabbitMQ是一个用erlang语言开发,在AMQP(高级消息队列协议)基础上完成的,可复用的开源企业消息队列系统。
几个概念说明:
- Broker:简单来说就是消息队列服务器实体。
- Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
- Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
- vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
- producer:消息生产者,就是投递消息的程序。
- consumer:消息消费者,就是接受消息的程序。
- channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程大概如下:
- (1)客户端连接到消息队列服务器,打开一个channel。
- (2)客户端声明一个exchange,并设置相关属性。
- (3)客户端声明一个queue,并设置相关属性。
- (4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
- (5)客户端投递消息到exchange。
- (6)exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
RabbitMQ集群方案原理
RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的。 下面先来看下RabbitMQ集群的整体方案:
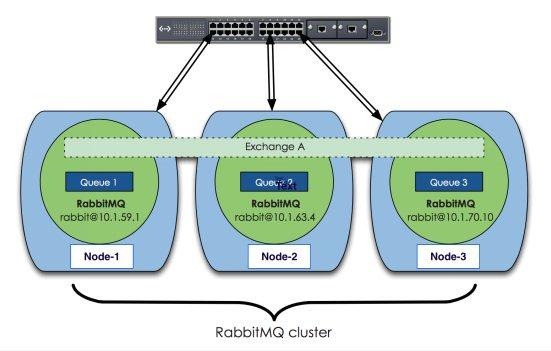
上面图中采用三个节点组成了一个RabbitMQ的集群,Exchange A(交换器,见基础概念)的元数据信息在所有节点上是一致的,而Queue(存放消息的队列)的完整数据则只会存在于它所创建的那个节点上。,其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
(1)RabbitMQ集群元数据的同步
RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):
a.队列元数据:队列名称和它的属性;
b.交换器元数据:交换器名称、类型和属性;
c.绑定元数据:一张简单的表格展示了如何将消息路由到队列;
d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;
因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue/user/exchange/vhost等信息都是相同的。
(2)为何RabbitMQ集群仅采用元数据同步的方式
我想肯定有不少同学会问,想要实现HA方案,那将RabbitMQ集群中的所有Queue的完整数据在所有节点上都保存一份不就可以了么?(可以类似MySQL的主主模式嘛)这样子,任何一个节点出现故障或者宕机不可用时,那么使用者的客户端只要能连接至其他节点能够照常完成消息的发布和订阅嘛。
我想RabbitMQ的作者这么设计主要还是基于集群本身的性能和存储空间上来考虑。第一,存储空间,如果每个集群节点都拥有所有Queue的完全数据拷贝,那么每个节点的存储空间会非常大,集群的消息积压能力会非常弱(无法通过集群节点的扩容提高消息积压能力);第二,性能,消息的发布者需要将消息复制到每一个集群节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加。
(3)RabbitMQ集群发送/订阅消息的基本原理
RabbitMQ集群的工作原理图如下:
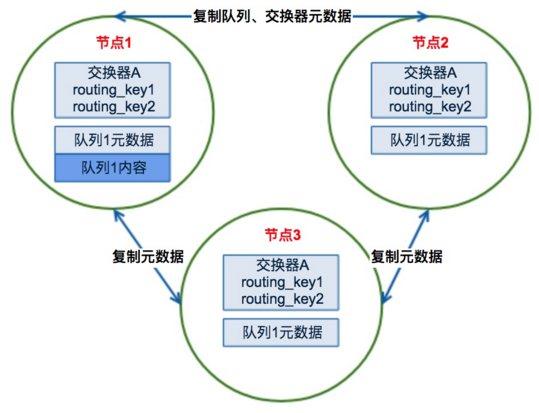
场景1、客户端直接连接队列所在节点
如果有一个消息生产者或者消息消费者通过amqp-client的客户端连接至节点1进行消息的发布或者订阅,那么此时的集群中的消息收发只与节点1相关,这个没有任何问题;如果客户端相连的是节点2或者节点3(队列1数据不在该节点上),那么情况又会是怎么样呢?
场景2、客户端连接的是非队列数据所在节点
如果消息生产者所连接的是节点2或者节点3,此时队列1的完整数据不在该两个节点上,那么在发送消息过程中这两个节点主要起了一个路由转发作用,根据这两个节点上的元数据(也就是上文提到的:指向queue的owner node的指针)转发至节点1上,最终发送的消息还是会存储至节点1的队列1上。
同样,如果消息消费者所连接的节点2或者节点3,那这两个节点也会作为路由节点起到转发作用,将会从节点1的队列1中拉取消息进行消费。
RabbitMQ集群搭建
| 主机 | IP | 角色 | 服务 | 端口 |
|---|---|---|---|---|
| centos-vm2 | 192.168.134.112 | disk | rabbitmq | 5672,15672,25672 |
| centos-vm3 | 192.168.134.113 | disk | rabbitmq | 5672,15672,25672 |
| centos-vm4 | 192.168.134.114 | ram | rabbitmq | 5672,15672,25672 |
端口解析:
- 4369: epmd对等发现服务
- 5672: rabbitmq服务端口
- 15672:rabbitmq web管理端口
- 25672: rabbitmq集群端口
角色解析:
- ram: 内存节点,节点将所有的队列,交换器,绑定关系,用户,权限,和vhost的元数据信息保存在内存中。性能更高,适合客户连接
- disc: 磁盘节点:节点将所有的队列,交换器,绑定关系,用户,权限,和vhost的元数据信息保存在磁盘中。为提供数据持久化及安全性,rabbitmq集群中至少需要一个磁盘节点,为避免单点故障,最好是设置2个磁盘节点
搭建步骤
1. 安装依赖
安装erlang(socat和logrotate依赖默认已安装)
1 | yum install erlang |
2. 安装rabbitmq
1 | yum install rabbitmq-server |
3. 配置rabbitmq
/etc/rabbitmq/rabbitmq.conf(此配置文件格式严格,注意列表最后一个值的逗号要删掉,不然会报错)
添加反向dns解析支持,能在管理页面看到节点主机名
1 | {reverse_dns_lookups, true} |
配置rabbitmq management
1 | {rabbitmq_management, |
/etc/rabbitmq/rabbitmq-env.conf
1 | RABBITMQ_MNESIA_BASE=/opt/rabbitmq/data # 数据目录 |
4. 同步erlang cookies
以centos-vm2上erlang cookies为样本拷贝到其它节点,保持相同的权限400
1 | scp /var/lib/rabbitmq/.erlang.cookie root@centos-vm3:/var/lib/rabbitmq/ |
5. 启动rabbitmq
1 | systemctl enable rabbitmq-server |
6. 初始化集群
选择一个节点做为初始集群节点,其它节点再加入集群:以centos-vm2为第一个disk节点,其它节点加入集群(加入前必须停掉app)
- disc节点加入
1 | rabbitmqctl stop_app |
- mem节点加入
1 | rabbitmqctl stop_app |
- 增加用户、管理员权限及镜像策略
1 | rabbitmqctl add_user mquser mqpassword #添加连接用户及密码 |
7. 添加rabbitmq management管理插件,支持Web界面管理(每个节点均要添加)
1 | rabbitmq-plugins enable rabbitmq_management |
登录:http://hostname_or_ip:15672
账号密码见上面设置
- 本文链接:http://www.whyvv.top/rabbitmq.html
- 版权声明:版权所有,转载请注明出处。
分享