Kafka集群搭建
它是一个分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。具有高水平扩展和高吞吐量。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
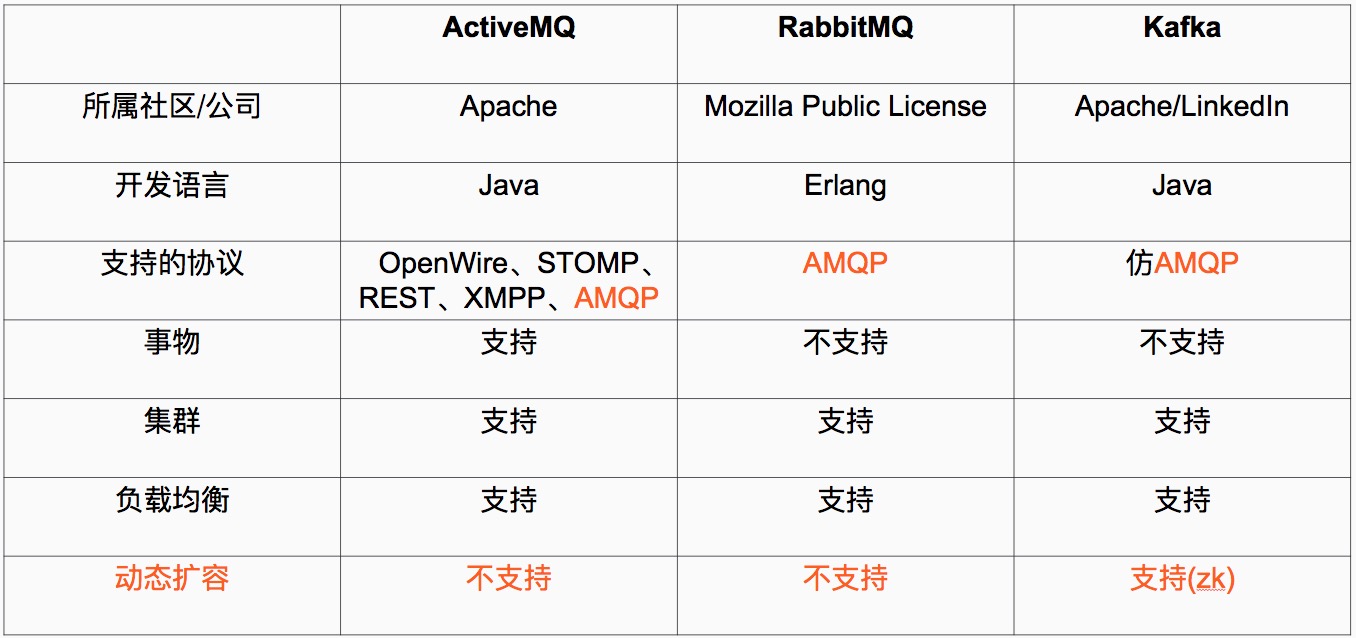
Kafka与其他主流分布式消息系统对比
基本概念
- 消费者:(Consumer):从消息队列中请求消息的客户端应用程序
- 生产者:(Producer) :向broker发布消息的应用程序
- AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
kafka支持的客户端语言:Kafka客户端支持当前大部分主流语言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ruby、Go、Javascript
Kafka架构
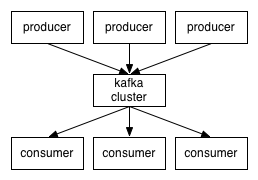
kafka集群中的消息,是通过Topic(主题)来进行组织的。
Topic
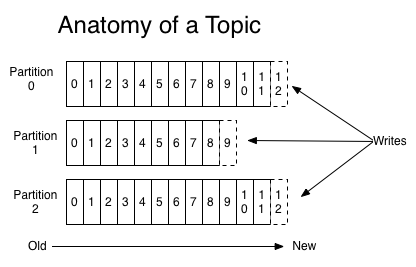
一些基本的概念:
- 1、主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
- 2、分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
集群工作图
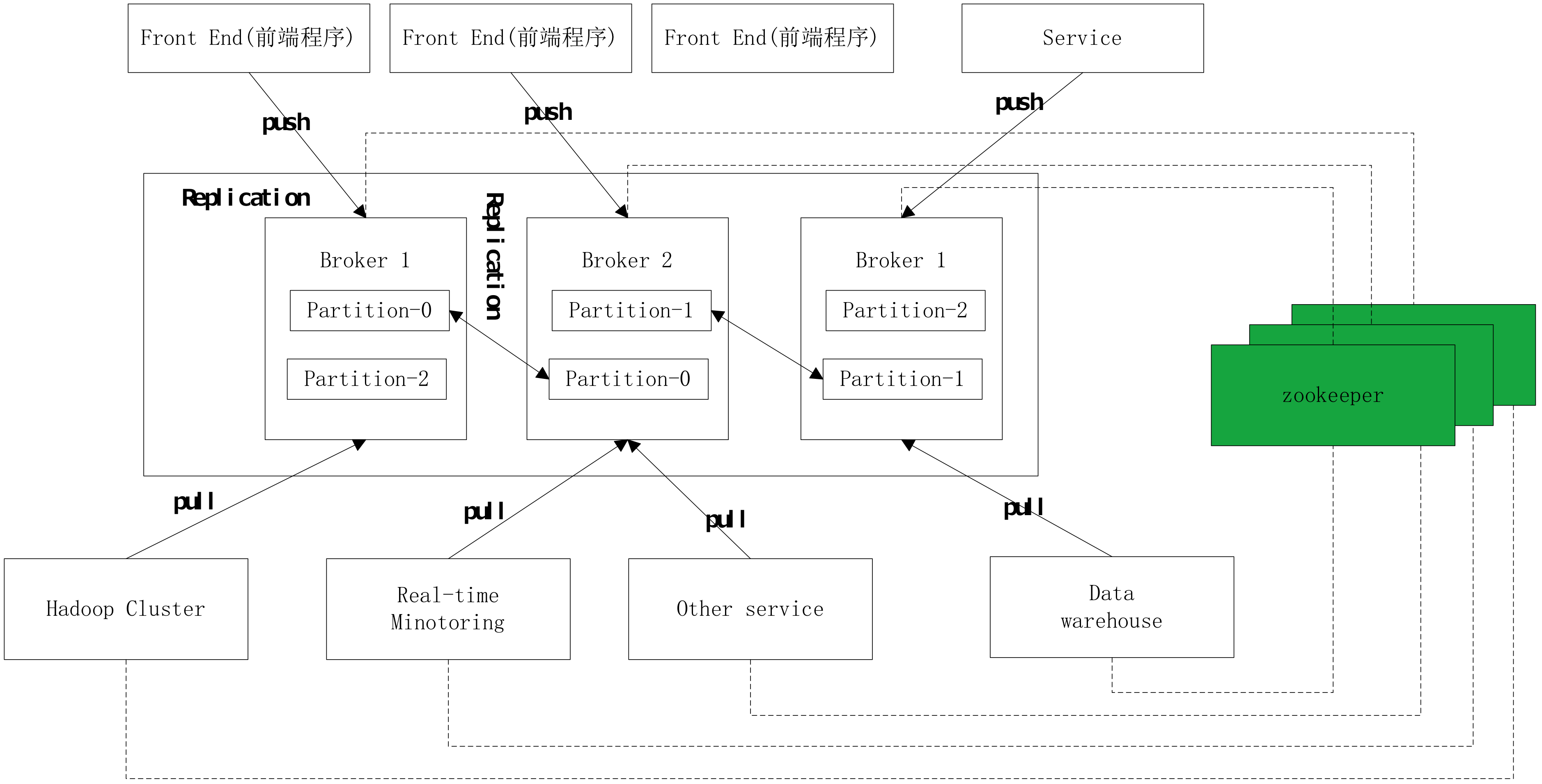
副本(Replication):为了保证分布式可靠性,kafka0.8开始对每个分区的数据进行备份(不同的Broker上),防止其中一个Broker宕机造成分区上的数据不可用。
无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
Kafka安装配置
| 主机 | IP | 角色 | 服务 | 端口 |
|---|---|---|---|---|
| centos-vm2 | 192.168.134.112 | slave | kafaka,zookeeper | 9092,8080,2181,2888,3888 |
| centos-vm3 | 192.168.134.113 | master | kafaka,zookeeper | 9092,8080,2181,2888,3888 |
| centos-vm4 | 192.168.134.114 | slave | kafaka,zookeeper | 9092,8080,2181,2888,3888 |
端口解析:
- 9092: kafka服务端口
- 8080: kafka管理端口
- 2181: zookeeper服务端口
- 2888: zookeeper集群通讯端口
- 3888:zookeeper集群选举端口
软件版本:
- kafka: 2.11.2-2.1.0
- zookeeper: 3.4.12
1. Zookeeper安装
见zookeeper安装文档
2. kafka安装
2.1 下载安装kafka
解压安装
1 | tar -zxvf kafka_2.11-2.1.0.tgz -C /opt |
2.2 配置kafka
配置文件/opt/kafka/config/server.properties
1 | broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样 |
主要修改以下几个参数
1 | broker.id=0 |
2.3 启动kafka
1 | /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties |
2.4 systemd支持
/usr/lib/systemd/system/kafka.service
1 | [Unit] |
启动kafka
1 | systemctl daemon-reload |
2.5 kafka集群验证
创建Topic
1 | ./kafka-topics.sh --create --zookeeper centos-vm2:2181 --replication-factor 2 --partitions 1 --topic test |
解释:
- –replication-factor 2 #复制两份
- –partitions 1 #创建1个分区
- –topic #主题为test
在一台服务器上创建一个发布者
1 | ./kafka-console-producer.sh --broker-list centos-vm4:9092 --topic test #控制台等待输入信息 |
在另一台服务器上创建一个订阅者
1 | ./kafka-console-consumer.sh --bootstrap-server centos-vm2:9092 --topic test --from-beginning #控制台等待接收发布者的信息 |
若成功接受到消息,说明集群搭建成功
Kafka-manager安装配置
kafka manager是管理kafka集群的web界面工具
1. 解压安装
1 | unzip kafka-manager-master.zip |
生成的zip包位置在kafka-manager-master/target/universal目录下,此处假设生成的包名为kafka-manager-1.3.2.1.zip
解压安装
1 | unzip kafka-manager-1.3.2.1.zip |
2. 配置
修改kafka-manager-1.3.2.1/conf/application.conf
1 | kafka-manager.zkhosts="centos-vm2:2181,centos-vm3:2181,centos-vm4:2181" |
添加systemd支持文件:/usr/lib/systemd/system/kafka-manager.service
1 | [Unit] |
3. 启动
1 | systemctl daemon-reload |
- 本文链接:http://www.whyvv.top/kafka.html
- 版权声明:版权所有,转载请注明出处。
分享